В Elasticsearch существует свой собственный язык запросов — Query DSL (в дальнейшем EQL).
Обладая широкими возможностями и гибкостью, он в тоже время крайне многословен и плохо читаем - основан на json .
В Kibana используется свой язык — Kibana Query Language
(KQL), основанный на Lucene Query Syntax
.
По сути KQL является надстройкой над EQL и призван облегчить взаимодействие пользователя с поисковой строкой.
В данном посте предлагаю пробежаться по основным возможностям KQL, а так же подсмотреть в каком виде запросы прилетают в Elasticsearch (в дальнейшем ES).
Для тестов я буду использовать набор nginx логов, предварительно загруженных в ES.
Загрузить файл с логами в ES можно напрямую через curl:
curl -H "Content-Type: application/x-ndjson" -XPOST http://localhost:9200/_bulk --data-binary "@<FILENAME_WITH_LOGS>" -u <YOUR_ES_USER>
Типичный экземпляр лога может содержать поля (часть опущена для краткости):
"message": "...GET /posts/golang-prometheus HTTP/2.0 ...Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:54.0)...Firefox/54.0",
"client.geo.country_name": "Russia",
"url.path": "/posts/golang-prometheus",
"user_agent": {
"name": "Firefox",
"version": "54.0"
}
Индексы, отображения и простые запросы
И так, начнем.
Допустим мы хотим отобразить все логи, где пользователи запрашивали страницу https://mixanemca.ru/posts/golang-prometheus .
Искать будем по полю message. Не долго думая вбиваем:
message:posts/golang-prometheus
И… результат нас не устраивает.
Да, мы видим те документы, которые хотели, но и кучу лишних со значениями:
posts/posts/gtd/
posts/
tags/golang/
...
Давайте разбираться что и почему.
Для просмотра полного запроса в json идем сюда:

...
"query": {
"bool": {
"must": [],
"filter": [
{
"bool": {
"should": [
{
"match": {
"message": "posts/golang-prometheus"
}
}
],
"minimum_should_match": 1
}
},
{
"range": {
"@timestamp": {
"gte": "2019-12-31T21:00:00.000Z",
"lte": "2020-03-31T20:30:00.000Z",
"format": "strict_date_optional_time"
}
}
}
],
"should": [],
"must_not": []
}
}
...
Именно в таком виде в ES прилетает запрос.
Здесь и далее будем фокусироваться на его сути, опуская второстепенные детали:
"match": {
"message": "posts/golang-prometheus"
}
Запрос имеет тип match .
Это стандартный запрос для полнотекстового поиска. Он возвращает коль сколько нибудь подходящие под него документы — удовлетворяющий как весь целиком, так и любую из его частей.
Про индексы
Полезно вспомнить как данные хранятся в индексах ES, точнее в индексах Lucene. Их еще называют обратными .
Представим, у нас есть несколько документов содержащие строки:
"posts/golang-prometheus" # Первый документ
"posts/gtd" # Второй документ
"posts/golang-errgroup/" # Третий документ
Обратный индекс примет вид:
"posts": {0, 1, 2}
"golang": {0, 2}
"prometheus": {0}
"gtd": {1}
"errgroup": {2}
Т.е. каждый документ разбивается на отдельные слова(токены), причем все символы токенов приводятся к их строчных аналогам. Такое поведение будет характерно для типа данных text .
Справа отображаются номера документов, откуда токены были извлечены. Занимается этим standard analyzer .
Поэтому ES возвратил документы как с искомыми полями, так и кучу “родственников”.
Исправляем ситуацию
Дабы отсеять лишнее, обернем запрос в двойные кавычки:
message:"posts/golang-prometheus"
и заглянем в json:
"match_phrase": {
"message": "get"
}
match_phrase – фразовый запрос, он “склеивает” токены вместе и выдает документы только со 100% совпадением.
Годится!
Это будет работать и в google search
Поиск по всему документу
Опустив имя конкретного поля, поищем совпадения по всему документу.
На выбор два варианта — использовать кавычки или нет:
"posts/golang-prometheus"
posts/golang-prometheus
соответственно за них отвечают и разные подтипы запросов:
### для поиска цельной фразы (вариант с кавычками)
"multi_match": {
"type": "phrase",
"query": "posts/golang-prometheus"
}
### для "свободного" поиска по всем вхождениям в запрос (без кавычек)
"multi_match": {
"type": "best_fields",
"query": "posts/golang-prometheus"
}
- multi_match
строит свой результат из склейки
matchзапросов по каждому полю документа; - Способ выполнения запроса будет зависеть от его типа:
- тип phrase
запускает
match_phraseдля каждого из полей; - тип best_fields возвращает документы при совпадением токенов.
- тип phrase
запускает
Разобравшись как выглядят индексы и простейшие запросы под капотом, рассмотрим еще несколько вариантов.
Регулярные выражения (regex)
Из
Wiki: Регуля́рные выраже́ния (англ. regular expressions) — формальный язык поиска и осуществления манипуляций с подстроками в тексте, основанный на использовании метасимволов (символов-джокеров, англ. wildcard characters).
Если простым языком, то regex позволяют задать шаблон выражения/строки, по которому происходит поиск в документе.
Стоит заметить, регулярные выражения работают только в Lucene Query Syntax
. Изменим режим поиска на lucene:
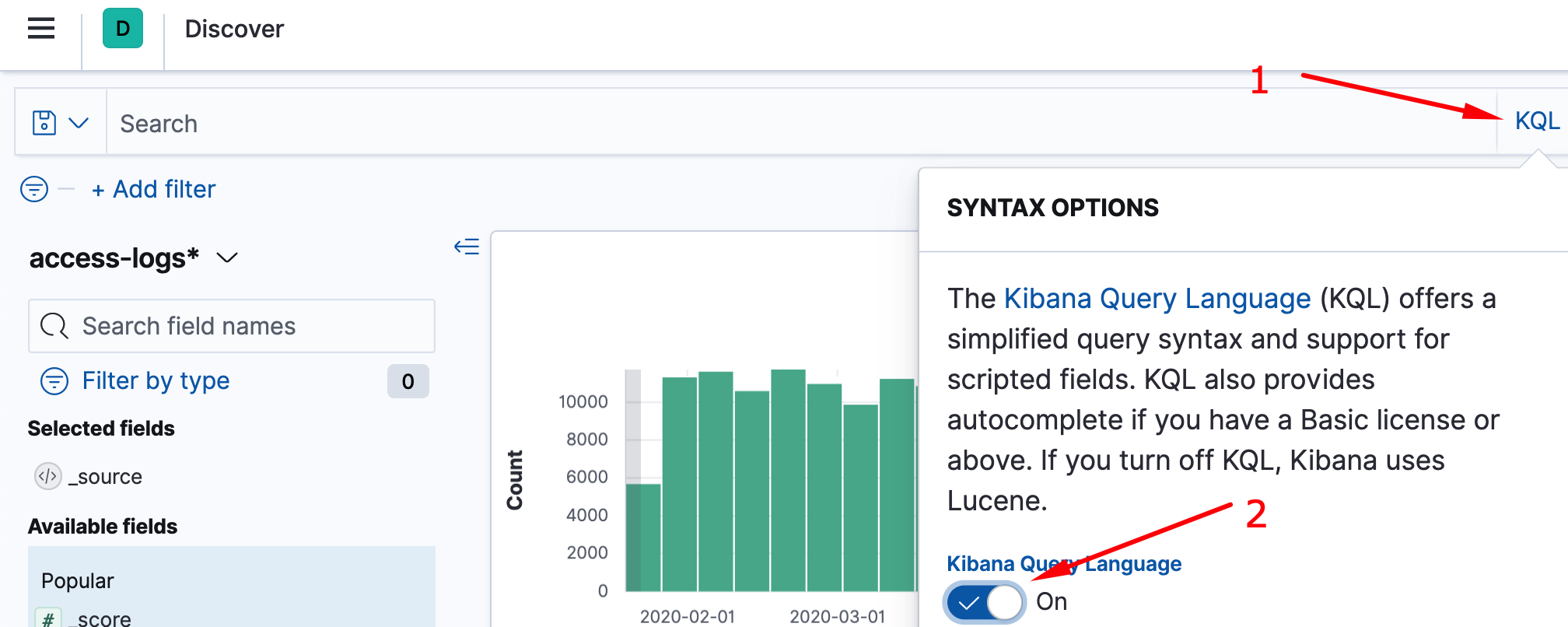
Для использования rexep требуется обернуть паттерн в две косые черты (/.../).
Для примера отобразим логи тех запросов, которые были отправлены из браузера Firefox с версий отличающихся от 54.0:
user_agent.name:Firefox AND user_agent.version:/[^5].\.0/
Давайте разбираться:
- В
user_agent.nameполе я указалFirefoxс большой буквы, т.к. тип у данного поля keyword .
Как так вышло, мы поговорим в следующий раз.
Но если коротко, при импорте лог-данных в ES, я предварительно загрузил index templates
для создания схемы данных.
В ней поле user_agent.name числится за типом keyword , а значения данного поля не приводятся к нижнему регистру при складировании в index.
user_agent.version:/[^5].\.0/- в поле
user_agent.versionмы ищем значения, первый символ которого не должен быть5; - далее идет управляющий символ
., олицетворяющий собой один любой символ;
- так как символ
.является зарезервированным, то для использования обычной точки (.) его требуется экранировать через\.
- в поле
regex синтаксис очень гибок, он позволяет описывать почти любые последовательности. Больше подробностей читайте по ссылке
.
Boolean запросы
Выше мы уже затронули оператор AND (логическое И). Существует оператор OR (логическое ИЛИ). Они относятся к Boolean запросам
.
Важно держать в голове, что AND имеет более высокий приоритет над OR и запрос:
user_agent.name:Firefox AND url.path:"posts/golang-prometheus" OR url.path:"posts/gtd"
вернет документы только с user_agent.name:Firefox и url.path:"posts/golang-prometheus", отбрасывая url.path:"posts/gtd".
Группировка
Для группировки запросов нужно поместить их в круглые скобки:
user_agent.name:Firefox AND (url.path:"posts/golang-prometheus" OR url.path:"posts/gtd")
На выходе мы получим логи посетителей статей golang-prometheus или gtd из браузера Firefox.
Операторы NOT и Plus
Оператор исключения - (NOT):
-client.geo.country_name:China
отобразит запросы из всех стран, за исключением Китая.
NOTи!являются синонимами
Оператор + (Plus) имеет обратную логику.
Wildcard queries
И напоследок операторы wildcard :
*(asterisk)?(questionmark)
Первый способен подменять собой 0 или более символов, второй ноль или один символ:
client.geo.country_name:A?gent*
Отобразит все запросы из Аргентины. Или Aдгента, если таковой имеется;)